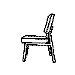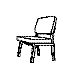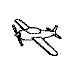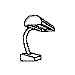InvarianceRotational Invariance
When an object is seen from a new viewpoint, the retinal projection may differ extensively
from the original viewpoint. According to Recognition-by-components (RBC;
Biederman, 1987),
if at least a subset of the original components can be recovered from the new viewpoint, and
their interrelations are unaltered, then recognition will occur. Object recognition in humans appears to occur despite
differences in viewpoint (e.g., Biederman & Bar, 1999; Biederman &
Gerhardstein, 1993),
but there has been considerable controversy regarding whether true rotational invariance
occurs (c.f., Biederman & Gerhardstein, 1995; Tarr & Bülthoff, 1995).
A growing literature has demonstrated that there are costs in recognition accuracy or speed
that are directly related to the degree of rotation from the familiar viewing orientation
(e.g., Bartram, 1974; Hayward & Tarr, 1997; Shepard & Metzler, 1972; Tarr et al., 1998).
These controversies are primarily relevant in discriminating between rival theoretical
accounts of object recognition (for more, see Overview and Theoretical
Considerations). Regardless of the exact mechanism by which novel viewpoints are recognized,
it is clear that humans do spontaneously recognize, to varying degrees, objects when seen from novel
vantage points.
Early evidence from studies of
rotation in the depth plane offered little encouragement that pigeons might also recognize familiar objects
from a variety of vantage points (Cerella, 1977; Lumsden, 1977). However, both of these studies employed training objects
which may not have provided effective three-dimensional information for generalization along the depth dimension
(Lumsden used a brick with an attached semicircle and Cerella used line drawings of regular and distorted cubes).
Logothetis et al. (1994) determined that
monkeys could recognize stimuli that were rotated in depth, and that generalization to novel viewpoints was better if
renderings of realistic objects served as a training stimuli than if wire-frame or blob-like shapes were used.
It is possible that viewpoint invariance may occur in pigeons, provided that they
are trained with richer, more realistic renderings
of objects that contain multiple cues for inferring three-dimensionality.
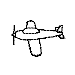
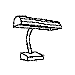
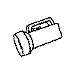
Training with a single orientation. Pigeons were trained with a
four-key
choice procedure to discriminate a chair, an airplane,
a lamp, and a flashlight (see below). Each group received only a single
viewpoint, but different groups of pigeons (n=4) received different
viewpoints: groups 0, 33, and 67 received training with viewpoints of 0°,
33°, and 67°, respectively.
Once the pigeons had learned the original discrimination task, they
were tested with novel orientations of
the training objects, ranging from -100° to 167°. Group 0 and
group 67 received three novel orientations on either side of the training
orientation and group 33 received four novel orientations on either side
of the training orientation. All three groups produced generalization gradients to the novel
orientations.
Choice accuracies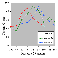 were highest for the original training stimuli. There
was a fairly symmetrical generalization decrement on either side of the
training stimulus, but even the most extreme orientations were recognized
above the chance level of 25% in all three groups. See Blough
(2001) for a further description and analysis of stimulus generalization gradients.
were highest for the original training stimuli. There
was a fairly symmetrical generalization decrement on either side of the
training stimulus, but even the most extreme orientations were recognized
above the chance level of 25% in all three groups. See Blough
(2001) for a further description and analysis of stimulus generalization gradients.
Although there was substantial generalization to novel viewpoints, a
result that stands in contrast to Particulate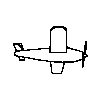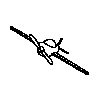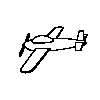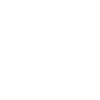 feature theory, the birds
did not demonstrate true viewpoint invariance. According to Biederman and
Gerhardstein (1993) three conditions must be met for viewpoint invariance
to occur: (1) the object must be decomposable into viewpoint-invariant
parts so that a structural description of the object's geons and their
spatial interrelations can be determined; (2) the structual description
of the object must
be distinctive; and (3) multiple views of the same object
must have the same structural description. The four training objects and
their rotated viewpoints do meet conditions 1 and 2, but not condition
3 because as the images are rotated in depth some parts are lost while
other are gained as in the animated example to the right.
feature theory, the birds
did not demonstrate true viewpoint invariance. According to Biederman and
Gerhardstein (1993) three conditions must be met for viewpoint invariance
to occur: (1) the object must be decomposable into viewpoint-invariant
parts so that a structural description of the object's geons and their
spatial interrelations can be determined; (2) the structual description
of the object must
be distinctive; and (3) multiple views of the same object
must have the same structural description. The four training objects and
their rotated viewpoints do meet conditions 1 and 2, but not condition
3 because as the images are rotated in depth some parts are lost while
other are gained as in the animated example to the right.
Training with
a multiple orientations. A second experiment examined whether training with multiple orientations
would enhance the degree of generalization to novel viewpoints by exposing
the birds to parts of the objects that were not seen during training with
only a single viewpoint. Logothetis et al. (1994) reported that training monkeys with
multiple views of a stimulus produced better generalization to rotated versions
than training with a single view. It is possible that multiple-view training allows
for a more complete specification of the stimulus parts, thereby allowing for superior
generalization to novel viewpoints in which the parts may be slightly altered.
Pigeons were trained with multiple viewpoints
of the chair, airplane, lamp, and flashlight. All four groups of pigeons
(n=4) received training at the nominal orientation of 33°. Group
33 only received training at this orientation. The other three groups received
training with two additional orientations at different degrees of separation.
Group 0, 33, 67 received additional drawings at orientations of 0° and 67°; group
-33, 33, 100 received additional drawings at orientations
of -33° and 100°; and group -100, 33, 167 received additional drawings
at orientations of -100° and 167°.
All four groups of pigeons received
the full set of test drawings from the first
experiment, ranging from -100° to 167°. The test drawings were incorporated
into sessions which also contained the original training trials. As can be seen
in the next figure,
Group 33 produced a generalization gradient that was similar in shape to the
gradients obtained in the
first experiment. Discrimination performance was maximal at the 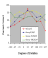 training
orientation of 33� and then fell off on either side as the objects were rotated
farther from the original viewpoint. All of the orientations were recognized
above the chance level of 25%. The other three groups of birds demonstrated a
much flatter generalization gradient than group 33. The degree to which the
gradient was broadened was related to the spacing of the training orientations,
with the most widely spaced training orientations (group -100,33,167) resulting
in the flattest generalization gradient.
training
orientation of 33� and then fell off on either side as the objects were rotated
farther from the original viewpoint. All of the orientations were recognized
above the chance level of 25%. The other three groups of birds demonstrated a
much flatter generalization gradient than group 33. The degree to which the
gradient was broadened was related to the spacing of the training orientations,
with the most widely spaced training orientations (group -100,33,167) resulting
in the flattest generalization gradient.
The results suggest that experience with multiple vantage points of an object
may counteract the effect of the alteration of the structural description of an
object that is produced by rotation in depth in these objects. However, template
models of visual perception would also predict superior generalization
performance when multiple training views are experience (for more see Overview
and Theoretical Relevance section).
The failure on the pigeon's part to demonstrate true rotational invariance, when trained
with only a single orientation may have
been due to the change in the structural description of the rotated viewpoints.
When an object is rotated in depth, it is possible for familiar parts to move out
of view and new parts to rotate into view. When pigeons were trained with three
widely spaced viewpoints they demonstrated relatively constant recognition accuracy,
suggesting that viewpoint invariance is achievable if all of the object's parts are
experienced in the training phase. The
demonstration that pigeons generalize to objects that are rotated in depth is
problematic for Particulate
feature theory because the local features change so drastically
with rotation in the depth plane. Although the structural description of an object also
changes with rotation in depth, those changes are less drastic than the changes in the
local features because most of the geons are still available, and their interrelations
are maintained. The demonstration of rotational invariance does not, however, necessitate
the use of recognition by components for theoretical explanation.
Template models (see Overview and Theoretical Relevance)
that allow for the storage of multiple views of an objects, or the use
of mental rotation in the search for a match, can also account for the above results
(also see Chase and
Heinemann (2001) for an account of template matching in pigeon object recognition).
Translational Invariance
When an imaged is viewed, its position on the retina likely changes from occasion to occasion. In
fact, even within a single viewing, the retinal position that the image activates likely changes with
movements of the observer's head and body. For the sake of processing efficiency alone, it seems plausible
that the visual system might independently code the shape and position of an object, so that a representation
of object shape would not have to be duplicated for every retinal position that is encountered. If such dual
representations were to exist (see Ungerleider & Mishkin, 1982 for indirect evidence in primates), it
would allow for effortless identification of object shape attributes, despite variations in position. As
a result, complete translational invariance would be observed. In humans, complete translational invariance
has been reported without any measurable costs in recognition accuracy or speed
(Biederman & Cooper, 1991;
Ellis et al., 1989). Cheng and
Spetch (2001) have demonstrated
the pigeons can learn to find a goal relative to one or more landmarks, even though the location
of the goal (and array of landmarks) moves about on the viewing screen from trial to trial. These
results indicate that location in the environment (here, the viewing screen) can be ignored by pigeons.
Although these results are encouraging, they do not speak directly to the issue of translational
invariance.
In order to determine the extent to which pigeons would demonstrate translational invariance in
their recognition of line drawings of objects, four pigeons were first trained to discriminate among four drawings of
a watering can, an iron, a desk lamp, and a sailboat using a four-key choice procedure. The training stimuli were presented in one of
four locations  on the
viewing screen: upper-center, lower-center, left-center, and right-center.
This was done to encourage attention to the entire viewing screen during training.
In order to receive reinforcement, the pigeon had to peck a particular choice
response key in the presence of an object, regardless of its location on
the viewing screen. Once the
on the
viewing screen: upper-center, lower-center, left-center, and right-center.
This was done to encourage attention to the entire viewing screen during training.
In order to receive reinforcement, the pigeon had to peck a particular choice
response key in the presence of an object, regardless of its location on
the viewing screen. Once the pigeons had achieved a high level of accuracy on the original discrimination,
they received the training objects in novel locations
on the viewing screen, randomly intermixed with occasions where the object appeared in its
original training location. There were four
novel locations: upper-left, upper-right, lower-left, and lower-right.
pigeons had achieved a high level of accuracy on the original discrimination,
they received the training objects in novel locations
on the viewing screen, randomly intermixed with occasions where the object appeared in its
original training location. There were four
novel locations: upper-left, upper-right, lower-left, and lower-right.
The next figure
presents the accuracy scores for the original and novel viewing
locations for  each of the four birds. There was no noticeable effect
of moving the entire object to a new location on the viewing screen (M = 85% correct), compared to
presenting the object in its normal location (M = 89% correct).
The successful generalization to novel locations indicates that the pigeon's
recognition of line drawings of objects is translationally invariant, much like
visual perception in humans.
each of the four birds. There was no noticeable effect
of moving the entire object to a new location on the viewing screen (M = 85% correct), compared to
presenting the object in its normal location (M = 89% correct).
The successful generalization to novel locations indicates that the pigeon's
recognition of line drawings of objects is translationally invariant, much like
visual perception in humans.
Although complete translational invariance was observed, the results should be interpreted with some caution.
A critical factor in observing translational invariance in the
pigeon is that the original training involve the presentation of objects in
more than one location. An earlier pilot study by Kirkpatrick-Steger and Wasserman
in which training objects were presented
solely in the center of the screen revealed only modest evidence
of generalization (approximately 50% correct) to new locations. Training with multiple locations may facilitate transfer
simply because the pigeon learns to attend to the entire screen. Alternatively, it is possible
that the original training explicitly taught the pigeons to ignore the dimension of location.
In any event, the effect of number and placement of locations in the training set on degree
of transfer to novel locations are factors that should receive further experimental attention.
Size Invariance
When a particular object impinges on the retina the size of the retinal image
often varies from occasion to occasion. The primary cause of retinal image size
variations is viewing distance. When an object is viewed from farther away, the
retinal image will undoubtedly be smaller than when the object is viewed from a
closer distance. Size constancy (or invariance) is the ability of the visual system
(in humans) to infer that a given object is the same size when it is viewed from
different distances. Size constancy allows for the recognition of an object, even though
the retinal surface area that the image activates is quite different. So, it is
possible to recognize both of the images to the left as the same parakeet, even though
one of the images is half the size of the other. A related phenomenon is the ability to use the retinal image
size to infer distance perception so that objects that are smaller are inferred as being
farther away. In a three-dimensional environment this inference would operate correctly, but in a two-dimensional image,
the inference can create illusions: Although the smaller parakeet is actually above and left-of the larger
parakeet, our visual system interprets the smaller bird as being in the distance. Combined, these two phenomena compose the size-distance problem, an
ability that allows us, as humans, to recognize an object from different distances and
to use the size of an object to aid in judgements about the object's distance.
from farther away, the
retinal image will undoubtedly be smaller than when the object is viewed from a
closer distance. Size constancy (or invariance) is the ability of the visual system
(in humans) to infer that a given object is the same size when it is viewed from
different distances. Size constancy allows for the recognition of an object, even though
the retinal surface area that the image activates is quite different. So, it is
possible to recognize both of the images to the left as the same parakeet, even though
one of the images is half the size of the other. A related phenomenon is the ability to use the retinal image
size to infer distance perception so that objects that are smaller are inferred as being
farther away. In a three-dimensional environment this inference would operate correctly, but in a two-dimensional image,
the inference can create illusions: Although the smaller parakeet is actually above and left-of the larger
parakeet, our visual system interprets the smaller bird as being in the distance. Combined, these two phenomena compose the size-distance problem, an
ability that allows us, as humans, to recognize an object from different distances and
to use the size of an object to aid in judgements about the object's distance.
Size invariance appears to occur readily in humans (Biederman &
Cooper, 1992; Fiser & Biederman, 1995), although in some paradigms recognition
may occur with a time cost (e.g., Jolicoeur, 1987). The present experiment addressed the issue of size constancy to determine whether
pigeons could recognize line drawings of objects that were larger or smaller than
their ordinary size. Pigeons can engage in both categorization (e.g, Bhatt et al., 1988;
Cerella, 1979; Herrnstein, Loveland, & Cable, 1976) and oddity-matching (Lombardi
& Delius, 1990) tasks when size was an irrelevant cue. These results indicate
that the pigeon is capable of classifying stimuli, even though their sizes differ.
(See Urcuioli
(2001) for further information and photographs of the kinds of stimuli employed in
categorization studies.)
The present study attempted to directly determine whether pigeons would continue
to correctly identify objects, even though their sizes had changed. Pigeons were trained with a
four-key
choice procedure to discriminate among the watering can, the iron,
the desk lamp and the sailboat. During the initial training phase, the pigeons only
experienced a single size of each stimulus, and all four of the training stimuli
were the same size. Once the pigeons were performing at a high level on the original
discrimination task they then received test trials in which the training stimuli
were either smaller or larger than the original size. There were seven test stimuli, three smaller,
three larger, and one original size. The test stimuli ranged from 25% to 250% of the original size.
The scaling was relative so that the aspect ratio of the altered stimuli remained the
same as the original size. Specifications of the height, width, and area of each stimulus can be found in the
adjoining table.
The next figure
displays recognition accuracy, in percent
correct, as
a function of relative 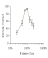 image size. Relative image size is scaled logarithmically to
equate the sizes in relative distance units. Performance was best to the original
training size, but there was substantial generalization to both smaller and larger
sizes. All of the images but the smallest size were recognized above chance. The
generalization gradient was somewhat asymmetrical: the decrement in performance was
more modest to larger sizes than to smaller sizes. This may have been due to the
fact that the larger sizes were not varied over as large of a range as the smaller
sizes, due to constraints of the size of the viewing screen.
(See
D. Blough's (2001) chapter for more on generalization gradients.) The results indicate that pigeons can recognize stimuli that have been altered
in size, but with a cost. The degree of cost is related to the degree of change in
the stimulus size. The implications of the cost in recognition accuracy is
discussed in the next section, and viewed in the context of the
results from studies on rotational and translational
invariances.
image size. Relative image size is scaled logarithmically to
equate the sizes in relative distance units. Performance was best to the original
training size, but there was substantial generalization to both smaller and larger
sizes. All of the images but the smallest size were recognized above chance. The
generalization gradient was somewhat asymmetrical: the decrement in performance was
more modest to larger sizes than to smaller sizes. This may have been due to the
fact that the larger sizes were not varied over as large of a range as the smaller
sizes, due to constraints of the size of the viewing screen.
(See
D. Blough's (2001) chapter for more on generalization gradients.) The results indicate that pigeons can recognize stimuli that have been altered
in size, but with a cost. The degree of cost is related to the degree of change in
the stimulus size. The implications of the cost in recognition accuracy is
discussed in the next section, and viewed in the context of the
results from studies on rotational and translational
invariances.
Next Section: Theory